
AI関連発明の有利な特許取得の進め方
こんにちは。北海道札幌の弁理士の常本です。
今回は、AI、IoT関連発明について特許を取得する場合、どの部分について特許を取得すると有利なのか、という点について検討してみます。
※2025年4月22日追記
本稿の続編として、下記のブログ(2025年4月7日公開)でより詳しい解説を記載していますので、併せてご参照ください。
R&D支援センター様の技術者・研究開発者向けセミナー「知財DX時代の特許調査効率化とAI技術の特許取得 ~AI×知財戦略の最前線~」のセミナーのご紹介 | 知財戦略パートナーズ
AI関連発明、IoT関連発明の効果的な特許の取得戦略について
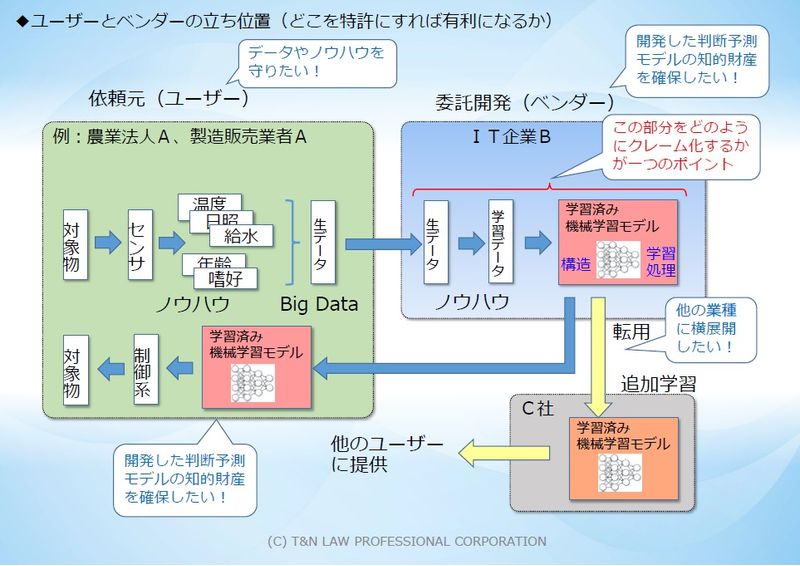
AI、IoT関連システムの場合、システム全体の特許を取得しただけでは、システムの一部である「機械学習モデル」を他の用途に「転用」又は「追加学習」する場合には特許権侵害に問えないという問題があり、開発した「機械学習モデル」の保護が課題となっていました。
例えば、下記のように、イ)所定のデータ(入力データと教師データ)を取得し、ロ)そのデータを用いて生成した予測モデルと、ハ)その予測モデルを使って予想した予測結果を出力する手段と、二)出力した予測結果に基づいて今後の生産量を策定し、ホ)生産計画を出力する装置(ないしシステム)、というシステム全体について特許を取得した場合を考えてみます。
この場合、イ)~ホ)のすべての手段を網羅しなければ、特許権侵害に問うことができず、ロ)の予測モデル(機械学習モデル)の再利用(追加学習して精度を向上させたり、他の用途に転用したりするなどの行為)については、保護の対象外になってしまうという問題があります。
- システム全体について特許を取得した場合
- 【請求項1】
イ)特定の商品の在庫量を記憶する手段と、
前記特定の商品のウェブ上での広告活動データ及び言及データを受け付ける手段と、
ロ)過去に販売された類似商品に関するウェブ上での広告活動データ及び言及データと、
前記類似商品の売上数とを教師データとして機械学習された予測モデルを用いて、
ハ)前記特定の商品の広告活動データ及び言及データから予測される今後の前記特定の商品の売上数を
シミュレーションして出力する手段と、
二)前記記憶された在庫量及び前記出力された売上数に基づいて、前記特定の商品の今後の生産量を含む
生産計画を策定する手段と、
ホ)前記出力された売上数と、前記策定した生産計画を出力する手段と、を備える事業計画支援装置。
(AI関連技術に関する特許審査事例〔事例 47〕 事業計画支援装置より抜粋)
- 【簡略化した請求項1】
イ)所定のデータ(入力データと教師データ)を取得し、
ロ)所定のデータを用いて生成した予測モデルと、
ハ)その予測モデルを使って予想した予測結果を出力する手段と、
二)出力した予測結果に基づいて今後の生産量を策定し、
ホ)生産計画を出力する装置(ないしシステム)。
この問題を回避するためには、「学習済みモデル」ないし「機械学習モデル」のクレームで特許を取得する必要があるのですが、通常、「学習済みモデル」ないし「機械学習モデル」は内部がブラックボックスで、これをどのようにクレーム化するかは難しい面があります。
言い換えると、内部がブラックボックスの学習モデルを権利化しても、侵害発見が難しいので、特許を取得しても効果が期待できないという問題です。
そこで、「入力する学習データと学習済みの機械学習モデル」までの部分でクレームを作成することが考えられます(図1をご参照)。
このような特許を取得できた場合、外部から、対象特許を利用しているのかどうか発見しやすいので(売り込みの際のアナウンスで、システムにどのようなデータを入力するかくらいは開示されているのが通例ですし、少なくとも、システムの仕様書には記載されるので、プログラムの内部に立ち入らなくても侵害を立証可能だからです)、特許を取得する意義を見いだせるというわけです。
もっとも、「学習済みモデル」はAIシステムの中核部分ですので、AIシステムを開発する際に、データを保有する事業者と、AIシステムを開発するITベンダーとの間で、どちらがどの部分の特許を取得するのかについて揉めることも多いので、事前に策を練っておくとともに、契約書に盛り込んでおくことが肝要です。
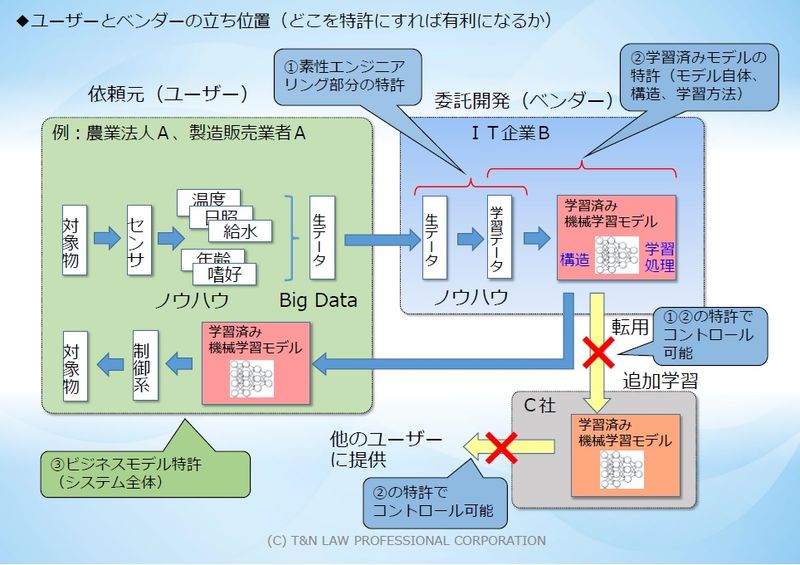
このように、どのようなデータに基づいて「学習モデル」を生成するのかという「素性エンジニアリング」(特徴表現エンジニアリングとも呼ばれます)の部分(図2の①)、もしくは、「学習データと学習済みモデル」の部分(図2の②)で特許を取得できた場合、前述のような、入力する学習済みモデルの再利用(追加学習して精度を向上させたり、他の用途に転用したりするなどの行為)についても特許権侵害に問うことができるので、AIシステムの保護範囲が格段に向上することになります(図2をご参照)。
各社の機械学習モデルの特許の取得状況について
(1)概要
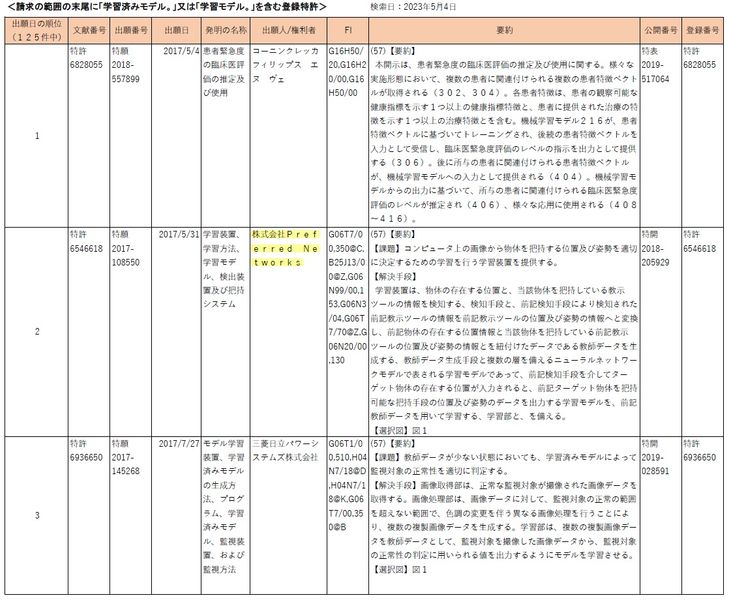
前回の2023年3月25日のブログ「道総研様のAI・IoT知財セミナー講師を務めました」でも言及しましたが、J-PLATPATで、請求の範囲に「学習済みモデル。」又は「学習モデル。」を含む、という検索条件で調べてみますと、これまで317件ほど出願され、特許を取得した例は、僅か125件程度であることが分かりました。
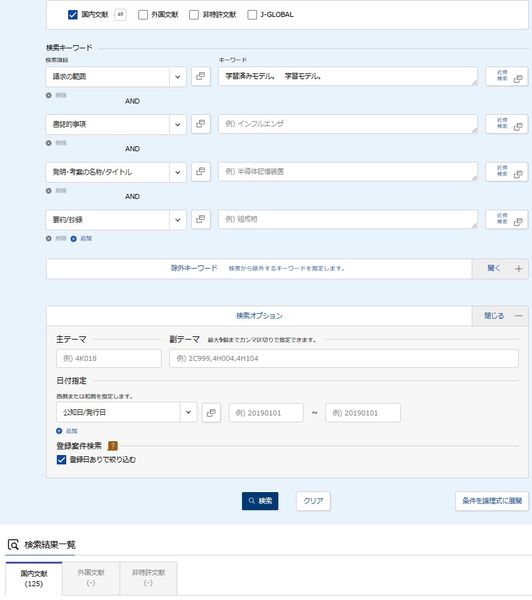
「学習モデル。」の検索結果
「学習済みモデル」の特許125件について、登録件数の多い順にリストを作成してみました。
大企業が多いですが、株式会社Preferred Networks社などのベンチャー企業の特許も含まれています。
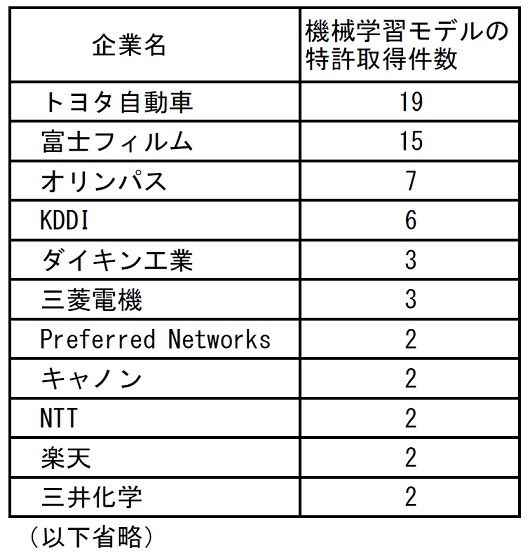
特許を取得した企業(件数順)
(2)日本で最初に「学習済みモデル」の特許を取得した企業は?
また、検索結果によれば、国内企業の中では、AI開発用のプラットフォームで有名な株式会社Preferred Networks社が最初に「学習済みモデル」の特許を出願していること分かりました(出願日は2017年5月31日、表2をご参照)。
⇒特許6546618「学習装置、学習方法、学習モデル、検出装置及び把持システム」
株式会社Preferred Networks社は、わずか200数十名規模の従業員で時価総額が3500億円と評価された会社だけに、いち早く有効な特許の取得にチャレンジしていたのは注目に値すると思います。
(株式会社Preferred Networks社の情報は「時価総額3500億円超のAIベンチャー企業、Preferred Networksに迫る」(2020.12.04 AI Now)の記事に基づきます。)
(3)当事務所で取得した「学習済みモデル」の特許について
2023年5月22日公開のブログ「特許調査を飛躍的に効率化するAI特許のご紹介(Part2)」において、当職個人の特許として、当事務所にて特許出願したAI特許がありますが、出願日は2019年3月20日でしたので、出願日順でみますと、登録された125件中の63番目でした(表3をご参照)。
なお、本件特許は、「素性エンジニアリング」(特徴表現エンジニアリングとも呼ばれます)の特徴部分(図2の①)、及び、「入力する学習データと学習済みの機械学習モデル」の特徴部分(図2の②)で特許を取得しているので、特許権侵害の発見も比較的容易ですし、学習済みモデルの再利用(追加学習して精度を向上させたり、他の用途に転用したりするなどの行為)についても特許権侵害に問うことができます。
.jpg)

