当事務所で特許出願した「特許調査を飛躍的に効率化するAI特許」のご紹介(Part2)
こんにちは。北海道札幌の弁理士の常本です。
2020年10月14日のブログ「特許調査を飛躍的に効率化するAI特許のご紹介」において、当職個人の特許として、当事務所にて特許出願したAI特許がありますが、このたび、無事、登録されましたのでご紹介いたします。
特許公報
【登録番号】特許第7226783号
【発明名称】情報処理システム、情報処理方法及びプログラム
【出願日】平成31年3月20日(2019.3.20)
【公開日】令和2年9月24日(2020.9.24)
【登録日】令和5年2月13日(2023.2.13)
本件特許の審査経過について
審査官との面接で伺った限りでは、新規性、進歩性は問題なく充足していると判断され、クレームのカテゴリーをどこまで許容するかが論点となっていたとのことでした。
通常一人の審査官が審査を行うとのことのですが、AI関連発明の中でも、かなり先駆的なクレーム構成となっていることもあって、数名の審査官で、どこまで許容すべきかを議論したとのことです。
出願した、イ)判定システム、ロ)学習処理システム、ハ)判定方法、二)機械学習モデル、ホ)学習データの構造、へ)学習済み機械学習モデルのパラメータの、6つのクレームカテゴリのうち、ホ)学習データの構造、へ)学習済み機械学習モデルのパラメータについては許容されませんでしたが、イ)判定システム、ロ)学習処理システム、ハ)判定方法、二)機械学習モデルの、4つのカテゴリーについては特許が認められました。
| 項番 | クレームカテゴリ | 審査結果 |
|---|---|---|
| イ | 判定システム | 〇 |
| ロ | 学習処理システム | 〇 |
| ハ | 判定方法 | 〇 |
| 二 | 機械学習モデル | 〇 |
| ホ | 学習データの構造 | × |
| へ | 学習済み機械学習モデルのパラメータ | × |
本件出願は、当職が企業から当事務所に移籍した直後の2019年3月に出願した案件で、まだAI特許の審査実務が固まる前の段階でしたので、お客様のAI特許の出願対応を行う前に、どのようなクレームが許容されるかを確認することも目的の一つにしていました。
本件出願により、目的の一つを達成でき、苦労して出願書類を作成した甲斐がありました。
なお、機械学習モデルのクレームで特許を取得する意義については、改めて、次回のブログ等でご説明したいと思います。
審査官との面接について
特許庁の審査官との面接については、特許庁に出向いて行う直接の面接のほか、電話やFAXやメールを使った電話面接のほか、ウェブ会議による面接などでも対応してもらうことができます。
北海道の場合、遠方であるため直接の面接を行うことは難しく、補正書をメールで送付したうえで電話やウェブ会議での面接をお願いすることが多い状況です(今回の面接は、補正書をメールで送付したうえで、お電話で相談しました)。
なお、審査官との面接については、日テレのテレビ番組「それってパクリじゃないですか?」の第5話「調整の樹海」でも取り上げられ、実際に特許の審査が行われる「特許審査室」のシーン、及び、「面接室」における面接シーンが放映されていました。現役審査官も審査官役としてゲスト出演しているとのことです。
番組の面接シーンでは、審査官がきっぱりと「これでは特許を認めることはできません」と伝えるシビアなシーンがあったり、逆に、「この視点はよいですね」などとざっくばらんに心証を明かしてくれる人間味に溢れるシーンなどがあったりして、確かに、実務の雰囲気が出ていると思いました。
<ご興味のある方はこちらをどうぞ!>
特許庁プレスリリース【特許庁】日テレ系4月期水曜ドラマ「それってパクリじゃないですか?」に撮影協力、現役職員も審査官役で登場!!をご参照
発明の特徴(再掲)
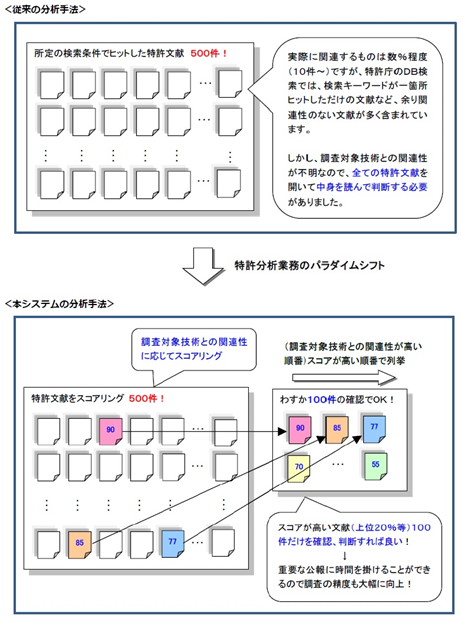
この発明は、特許や論文などの文献調査をAIで効率化する技術で、調査時間を1/5~1/10に低減することを目標にしています。検索キーワードと文献との関連性を判定してスコアリングし、関連性の高い順にソートして提示することで、スコアが高い文献、例えば、全体の1~2割ほどを確認すれば済むようにする技術です。
仕組みとしては、ベテランの調査者(サーチャー)の判断結果を機械学習し、文献中における検索キーワードの分布や、ヒットした検索キーワードどうしの位置関係に基づいて、検索キーワードと文献との類似性を判定する点に特徴があります。
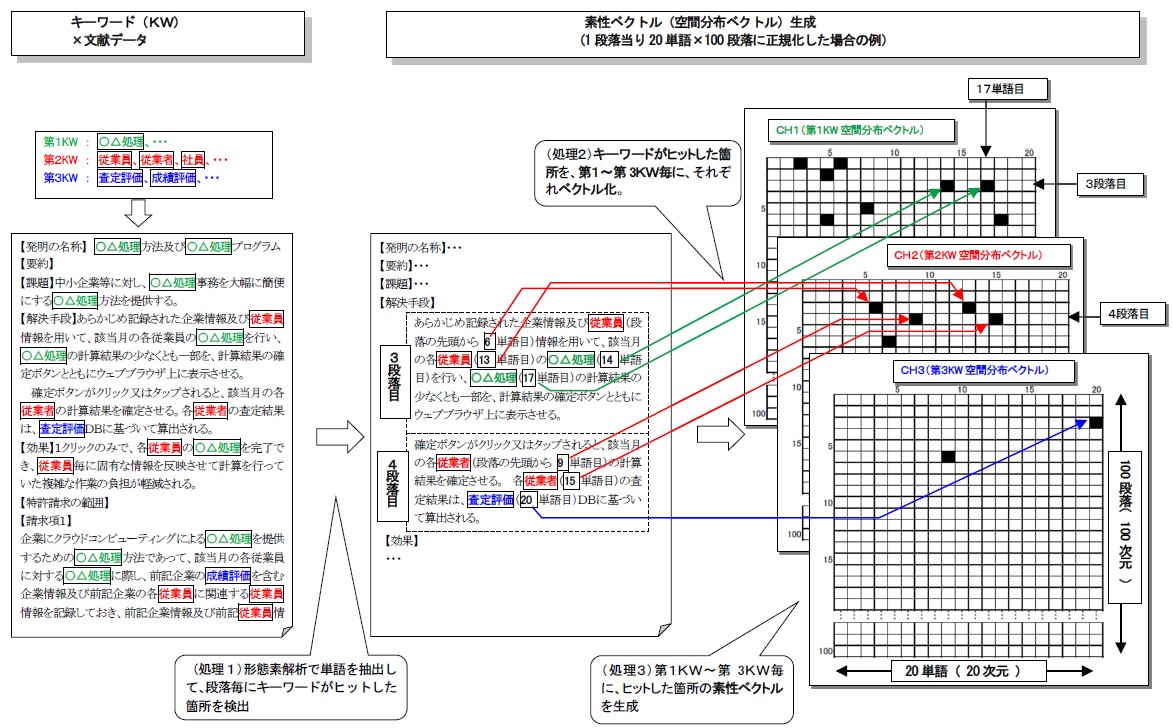
発明の詳細(再掲)
本発明は、検索キーワードとして、第1段「センサ」×第2段「動物」×第3段「体調」などのように、第1段~第n段に多段的に設定する場合において、文献中の第1段~第n段の検索キーワードの存在箇所を解析して、第1段~第n段の各段の検索キーワードごとに、検索キーワードが文献中にどのように分布しているのかを示すKW空間分布ベクトルをそれぞれ生成し、生成した第1段~第n段のKW空間分布ベクトルに基づいて、検索キーワードのセットと文献との関連性を判定するようにしています。
ポイントは、第1段~第n段の各段の検索キーワードごとに、それぞれKW空間分布ベクトルを生成することで、ヒットした各段の検索キーワード相互の位置関係を把握し、文献との関連性を判定する点にあります。
ある意味、調査者(サーチャー)の脳内(右脳)で行われている「直感的な判断」を機械学習で実現する技術と言ってよいのかもしれません。
藤井聡太氏(六冠)が詰め将棋を解く際に「頭の中では、一手一手の手順をトレースせず」に、「もっと抽象化されたイメージのようなものを描いて判断している」といわれていますが(杉本昌隆著『悔しがる力』ご参照)、ベテランのサーチャーも、「文献に記載された文字列をつぶさに読んで判断」するというよりも、むしろ、「ヒットしたキーワード同士の位置関係や分布で関連性をある程度判断している(ある種のイメージ処理に近い)」ということに着目し、これを機械学習で実現する仕組みを考えてみたというわけです。
もちろん、機械学習を利用するので、事前に、ベテラン調査者の数万件の調査結果を学習させておき、学習済み機械学習モデルに刻み込んだ関連性判定のパラメータに基づいて、検索キーワードのセットと文献との関連性を判定するということになります。